
Clay would’ve charged me $40,000. I spent $225.
Build-vs-buy logic flipped in the AI era. The credit math, the time tracking, and the moat that isn't the code.

My targets share a shape: B2B product companies with PMF, outsourced dev, and a tech gap in leadership. They don’t live on one platform... they sit at the intersection of a dozen: Clutch, dev job boards, ProductHunt, G2 pre-Series B.
The obvious tool for stitching those signals is Clay.com, a brilliant product. It’s the $5B-valuation category leader, $100M ARR. In 2026, GTM stack = Clay.
It’s also a metered credit machine built for well-funded sales teams and it doesn’t cover half the sources and signals I actually need.
So I built my own. Over two months.
What I actually built
In plain English, a database that does three jobs:
Pulls in companies and people from ProductHunt, G2, Clutch, LinkedIn, job boards, Google search, …
Cleans and merges them into one master view. No duplicates.
Scores every company on fit. Hard rules first (size, country, hiring signal, CTO presence). Then AI for the judgement: product or agency? PMF? founder type?
Under the hood: TypeScript CLI on Postgres. Two AI scoring passes. One cheap (OpenAI gpt-4.1-mini via Batch). One premium (Claude Sonnet with Opus escalation, on my Claude Code subscription).
The current dataset, after two months:
38,719 unified (pre-filtered) companies
139,522 unified people
202,370 PDL company rows (bulk CSV → DuckDB)
49,772 DataForSEO SERP queries fired
44,769 website scrapes
28,000 ATS jobs (Greenhouse, Lever, Ashby, Workable, SmartRecruiters)
~17,300 job board jobs across 5 boards (Wellfound, WWR, RemoteOK, ...)
16,160 AI scoring runs (multi-pass)
143,283 Clutch reviews (no Clay native provider)
15,492 Clutch agencies
82,633 G2 products + sellers
39,306 ProductHunt products

Where the time actually went
Per my Timing app, the actual breakdown:
~92h pure coding (IDE + terminal) ... 44%
~43h Claude Code as agent (preparing lists, insights, scoring) ... 21%
~35h manual outreach (LinkedIn, CRM in the browser) ... 17%
~35h research (+ Obsidian) ... 17%
About half was pure coding. The other half was running the pipeline on live outreach. To be clear: the agent never sent a single DM... that’s still me, manually. What it did do was generate the queue: who to connect with, who’s worth a DM today, what to mention. The system is a pipeline plus helpers, not an outreach autopilot.
This wasn’t “build, then use.” It was “build while using.” Every gap in the data I noticed while sending DMs became a scraper or a query the next day.
My actual spend
DataForSEO SERP ... 49,772 × ~$0.002 = $98.70
OpenAI API ... 16,160 gpt-4.1-mini calls at 50% batch = <$25
Claude Code subscription ... 2 mo × $100 × ~50% allocation = ~$100
Postgres, Playwright, DuckDB, PM2 ... all local, $0
PeopleDataLabs ... 5GB free CSV → DuckDB, $0
LinkedIn data ... browser-based, manually, $0
Twenty CRM ... self-hosted, $0
Total: ~$225
What Clay would charge for the same output
Clay charges in credits. April 2026 pricing - I’m using $0.05/credit as my blended rate: it’s based on the public pricing I could find. Conservative one-time cost for my rows:
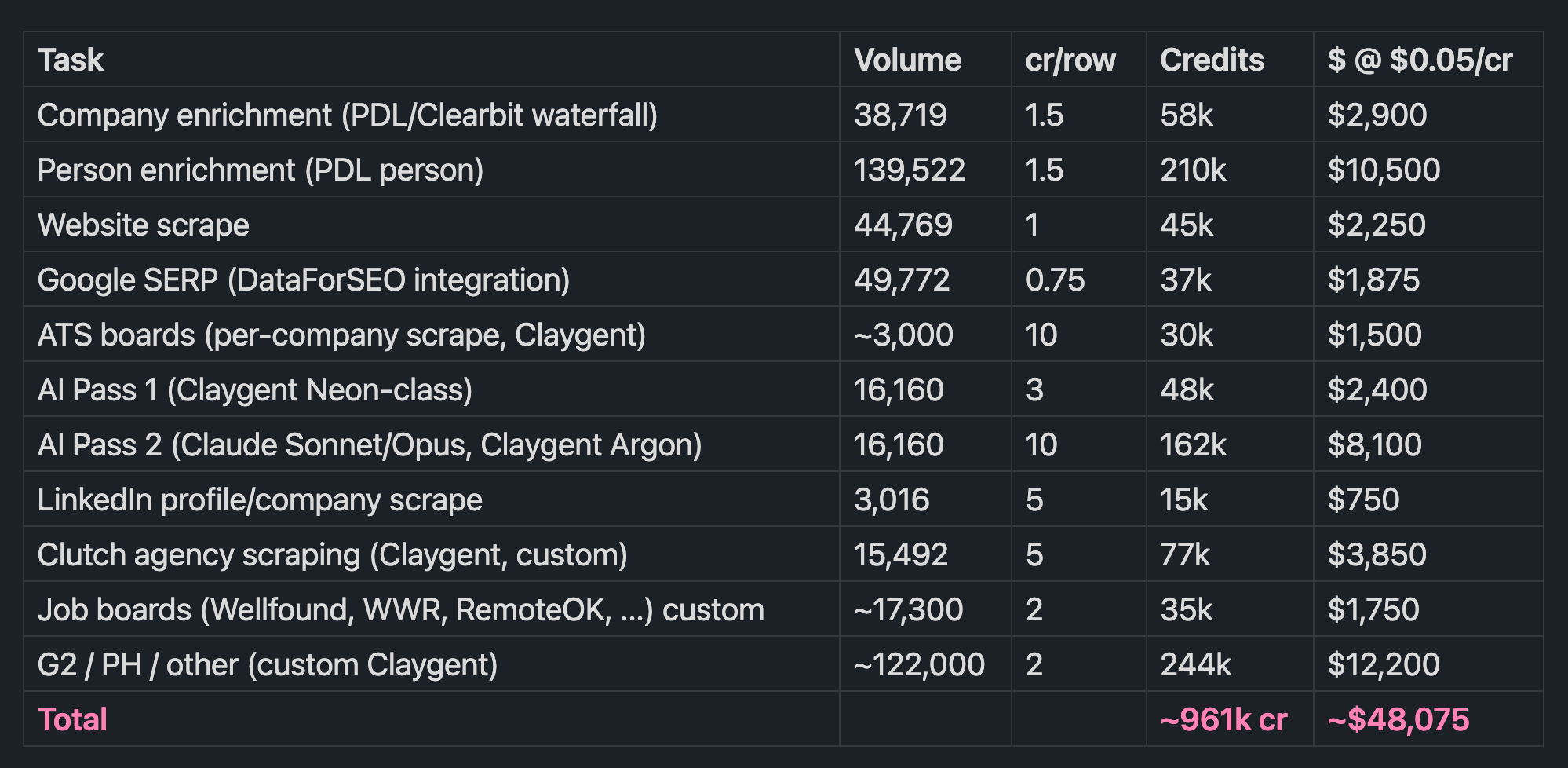
961k credits is 13× the annual Growth cap. At that volume Clay sales steers you to Enterprise. Vendr claims their median is $50k/yr (max reported $116k).
Realistic Clay bill for exactly this dataset, one-time: ~$40,000–60,000.
All numbers are from my production Postgres as of 2026-04-26. Clay credit math uses Growth-tier rates from Clay’s post-March-2026 pricing ($0.05/credit, with the 50% credit reduction Clay claims on most-used enrichments).
The three arbitrages
1. PeopleDataLabs bulk CSV → DuckDB
PDL publishes a 5GB free company dataset with 35M rows. I imported it into a persistent DuckDB file once (<5 minutes, one-time), then used four-tier matching against my companies: LinkedIn URL → domain → normalized name + country → normalized name.
Result: 202,370 PDL rows accessed across 31,129 matched companies, at $0.
Inside Clay, the same dataset is accessed per-row at ~1.5 credits per lookup (post-March-2026, after Clay’s claimed 50% credit reduction on popular enrichments). 202,370 × 1.5 × $0.05 = $15,178.
This one move is ~32% of the entire delta.
2. OpenAI Batch API + a flat-rate Claude subscription
Three-pass scoring:
Filter first, no AI. SQL/TypeScript heuristics on signals I already have (size, country, hiring shape, CEO presence, review density). No cost. ~38k companies → a few hundred eligible for expensive scoring.
Cheap AI at scale. gpt-4.1-mini via OpenAI Batch. Batch = 50% off. One prompt per company. 5+ judgement calls (product vs agency, PMF, founder type, CTO gap, buyer stage) + 0–100 score. 16,160 calls came in under $25.
Premium AI on subscription quota. Claude Sonnet (with selective Opus) via the Claude Agent SDK. Runs on my $100/mo Claude Code subscription. Marginal cost: zero. I’d pay for it anyway.
Clay’s AI columns charge credits per run regardless of batch-ability, and their frontier-model credits are token-metered on top. Same passes in Clay = ~$10,500... and the deterministic pre-filter wouldn’t exist there at all, so you’d be running AI columns on the full 38k.
3. Custom scrapers for sources Clay doesn’t have
Clutch reviews, job board listings, ProductHunt maker LinkedIns, G2 seller HQs... none of these have native Clay providers. In Clay you’d run Claygent against them, which is both expensive (credits per page) and brittle (retries burn more credits).
I wrote Playwright scrapers once. They run via PM2 loops.
Bonus: my scrapers don’t loop forever. Public Clay community threads document Claygent re-running infinitely on prompts that worked for months, costing some users $500/week in unintended API spend. Owning the scrapers means owning the kill switch.
Same sources in Clay, conservatively: ~$17,800.
What Clay does better
This isn’t a “Clay bad” post. It’s excellent at things I gave up:
Teams. Clay is multi-player. My stack is single-operator.
No-code. Clay users don’t touch TypeScript. My stack assumes you can read code and SQL.
Reliability. Clay has uptime SLAs. Mine has end-to-end ownership: I know every part and can fix anything fast.
Number of native providers. Clay covers 150+ data sources out of the box. Hunter, Apollo, ZoomInfo, Smartlead, Salesforce, HubSpot. I have under 10 I care about.
Discovery. Clay’s people-search finds prospects I’d have to go scrape myself.
Time-to-first-campaign. A Clay user ships a campaign in a day. It took me weeks to get it initially running.
Clay also invented this whole category. The “GTM Engineer” role exists because they built the workflow that needs one. I’m not saying they’re overpriced. I’m saying they’re the wrong tool for my exact task.
If I were a five-person GTM team targeting a generalist ICP covered by native providers, Clay is the obvious choice.
When building beats buying
My arbitrage stacked because of a specific shape:
Niche ICP. Targets are mostly US. Right ones don’t show in Apollo nor Clay. Signal lives on long-tail platforms...
Single operator. No team to onboard.
High volume per prospect. I want 10+ signals per company. Clay charges per signal. For my stack I simply add a scraper once and for all.
I already pay for Claude Code.
Flip any of those and buying Clay wins.
Clay would’ve changed my whole approach
Here’s what the cost math doesn’t show.
If I’d used Clay, my whole approach would’ve been different. More narrow. More focused. Every signal costs credits, so before pulling anything you ask yourself: “is this worth the credits per row?” That’s a fine question if you’re a sales team on a budget. It also quietly kills exploration.
Owning my own DB removes the question. Once a Playwright scraper is written, scraping 50,000 rows costs the same as scraping 500. So I went broad. Half of it turned out to be noise. The other half exposed signals I wouldn’t have known to ask for.
The intersection-of-platforms thesis only works if you can afford to be wrong about which platforms matter. Clay can’t afford that. I can.
The moat isn’t the code
If I open-sourced this repo tomorrow, nobody could use it as-is. ~60k lines of TypeScript across a CLI, a Next.js web app, and an MCP server... platform scrapers, AI scoring and drafting (Claude + OpenAI), Postgres with 57 migrations, a Twenty CRM sync layer with merge and qualification logic. Substantial surface area. And it took <100h of actual coding.
In 2026 the bottleneck isn’t writing code. It’s knowing what to build.
The moat is the data model: three all_* tables on top of keyed platform stagings, with FK-linked enrichment rows and idempotent re-scrapes. The schema encodes a specific thesis: that the right targets leave fingerprints across many public surfaces, and the intersection is the signal. Change the thesis and the whole schema changes.
Clay is a spreadsheet for people who don’t have a thesis yet. That’s its superpower and its price. If you do have a thesis (one sharp enough to justify three months of Postgres migrations), Clay is paying a toll for flexibility you don’t need.
TL;DR
Right tool for teams with a generalist ICP. Wrong tool if your ICP is sharp and you can write TS & SQL.
Three arbitrages drove the gap: PDL’s free bulk dataset, flat-rate Claude Code quota, Playwright scrapers for sources Clay doesn’t cover.
Clay for the same enrichment volumes: ~$40,000–60,000.
My stack: ~$225.
If you’re working through a similar build-vs-buy in 2026, DM me on LinkedIn or WhatsApp.
I’ll be posting more in this series as I work through other AI-era trade-offs.